
Note: when referring to a Python snippet, the reader may get it at : https://gist.github.com/ijkilchenko/a57afc3603772cd02d75
Cryptographic Hash Functions
Cryptographic hash functions are the things that turn your passwords into less interpretable and random looking output. The SHA-256 function will, for example, give you (in hexadecimal)
'0e024e5ab7654161d9ee..ded7'
if you use mycat123 as your password. This looks random, but it’s actually not. In fact, you will get the same hexadecimal value every time you enter mycat123. That’s one of the nice properties of cryptographic hash functions. There could be other words that produce that hexadecimal output, but it’s computationally difficult to find them. You would have to go through each possible combination of letters and numbers and symbols (the alphabet of things that make up a password) in order to find the words that produce a given output. If you know the alphabet/vocabulary needs to be all lowercase letters and numbers, this might help you.
When you log-in to a website, the site only stores the hash (the output of the cryptographic function) permanently and your original password (such as mycat123) is only used temporarily to check if it produces the expected hash. So when a website gets broken into, the hashes are the only things, usually, which could be stolen, not your original passwords. Arguable, the hashes are useless to gain entrance into the website. This is really the nicest property of these functions — in order to compute the inverse, you have to try almost all possible input words and any computer will not be able to hold enough word to hash pairs for all possible phrases except short ones and common ones (such as from an English dictionary). But this really is the interesting thing about rainbow tables — you can greatly compress such pairs and you can inverse many hashes quite efficiently.
Rainbow Tables
A rainbow table is an attempt to compress your password cracking data structure. The overall idea is to partition the space of all possible inputs, or more concretely, the space of all possible passwords, and store each partition efficiently. There is a trade-off, you will be able to use less memory at the expense of not being able to look up the inverse to every hash as quickly as if you stored the whole data structure without the rainbow table trick. So there is a computational cost involved and the first trick is to be able to generate new passwords from hashes and this is where reduction functions come in.
Reduction Functions
A reduction function is simply a function that maps from the space of outputs of a hash function back into the space of inputs of a hash function. If SHA-256 produces
'0e024e5ab7654161d9ee..ded7'
when you type in mycat123, then a reduction function 
greenforest55 when you type in
'0e024e5ab7654161d9ee..ded7'.
It’s critical to note that 
As you might predict at this point, we use reduction functions along with our original hash function to create a chain of input to output pairs. We might do something like

So again, the reduction function
First of all, we want to reliable map a hash back into a word. This makes our hash-reduction chains deterministic. This also means that given a starting word, we can generate the whole sequence of word-to-hash-to-word tuples on the fly. This is how we will partition our space of all possible passwords, by hash-reduction chains up to some size 
If forest, our hash-reduction chains will quickly start a cycle (right after the first iteration) and in order to partition the whole space of passwords, we will need a chain for each password — not much of a compression technique. So
Generating i-th Word
The usual method to ensure that the 


def R(hashvalue_in_hex): i = int(hashvalue_in_hex, 16) % 10000 return i
There is an assumption that the last 4-digits of the hashvalue are themselves uniform and so truncating to those digits gives a uniform distribution.
Fine, so now we can make a function
If we could list all valid passwords (letting there be 

Let vocab = 'abc' and we are interested in getting the 5th valid length 4 password over this alphabet/vocabulary. Listing the possibilities in lexicographic order,
- aaa | 0
- aab | 1
- aac | 2
- aba | 3
- abb | 4
- abc | 5
- aca | 6,
- …
we see that abc is the 5th valid word that we want to generate on the fly. Please note that the decimal number 5 is really 012 written in base 3. Since our vocabulary is of length 3, we can interpret any base 3 number as a direction to get one of three letters for each position. In this case, 012 says to put 0th letter, followed by the 1st letter, and finally followed by the 2nd letter in our vocab = 'abc'. This, as a coincidence, gives us abc. Additionally, decimal number 6 is 020 in base 3 which gives us the element aca.
This idea completes our reduction function which is very convenient if we know the alphabet/vocabulary of all passwords a priori. Here is a Python example of how to do just this if i is a decimal hashvalue and we want to get the corresponding password as the output of our reduction function 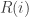
def base10_to_baseB(num, B):
digits = []
while num > 0:
p = math.floor(math.log2(num) / math.log2(B))
d = math.floor(num / (B ** p))
num = num - d * B ** p
if not digits:
digits = [0] * (p + 1)
digits[len(digits) - 1 - p] = d
return digits
choices = base10_to_baseB(i, len(vocab))
word = [vocab[j] for j in [0 for _ in range(0, n - len(choices))] + choices]
word = ''.join(word)
The above snippet generates the i-th word in lexicographic order from the space of all possible words with a vocabulary of vocab (a Python string).
So the reduction function will combine the two ideas from above: we get a uniformly distributed decimal number in n in the above snippet).
Computing the Chains
Now that we have a stable way to generate long sequences of hash to word values, we do just that up to some length 
Given some new hashvalue that we would like to reverse, we simply iteratively compute
There are some subtleties that can happen. Different chains, even from different starting words, may merge as we really do have very little control over the output of our reduction function. As such, we might end up wasting computing time calculating any two similar chains. The next idea of rainbow tables is to actually use multiple reduction functions 

for some 

Finally, we cannot guarantee that a given hashvalue will be present in any of the chains because our starting words are a random sample of size
Even more interesting is that although rainbow tables seem to be an algorithmic nightmare to the supposedly secure transactions that we do every day, they can easily be defeated if a website that you use salts the password, effectively generating a different cryptographic hash function for each user. The benefit of using rainbow tables in this case is eliminated.
All ideas summarized above are available as a Python script here as a GitHub gist : https://gist.github.com/ijkilchenko/a57afc3603772cd02d75. Note: I attempt to generalize the ideas above in the case that some chains do merge for one reason or another by storing the rainbow table in a Python dictionary. Each key is the ending of a chain with a value of a list of starting words (which generate chains that end at the key).
Space and time complexities of the script.
- Let
be the size of the vocabulary (number of unique letters in the Python string
vocab) - Let
be the desired password length
- Let
- Let
be the number of reduction functions used (the Python script defines a number of salts and uses a different salt per reduction function effectively making new reduction functions)
- Then
, the number of possible passwords
- Then
, the time to generate the rainbow table
- Then
, the space to store the rainbow table (the original space without using the rainbow table tricks would be
- Finally, the computation of the inverse for a given hashvalue is
since we have to perform at most

Hello,
Thanks for the reduction explinations, but would it be possible to get the Reduction-function in Java code?
How would we store those end-hashes? would we need a treeMap for the start and end text?
Thanks again